
The international AOIR has a great ongoing discussion about ethics of doing social media research, including 2012 recommendations for researchers and a wiki that you can contribute to. Check it out!
research ethics 2.0: association of internet researchers
Categories: General
Comments Off on research ethics 2.0: association of internet researchers
Proposal: Talk about the Human Communications Science Virtual Lab
The HCS vLab is one of the Australian Government funded NeCTAR eResearch projects.
Human Communication Science (HCS) is a broad-reaching interdisciplinary mix of research that spans speech, language, sonics and music; and HCS research encompasses areas such as speech science, computer science, behavioural science, linguistics, music cognition and musicology, and sonics and acoustics.
The virtual lab:
- Brings together diverse data sets for the first time into one discovery/repository system, including text, audio and video resources with rich metadata.
- Links the data to tools – both inside and outside the lab, from simple bread-and-butter linguistic tools like concordance (keyword-in-context) searching and word frequency analysis to processing data using programming languages such as Python and R.
- Has a workflow system we borrow from the the bioinformatics community – Galaxy, where users will be able to chain-together complex processing pipelines on data.
Who might be interested? Anyone interested in text, audio, video processing of any kind will eventually have access to the vLab or be able to run their own version of it.
We’re proposing to give a demo and talk about how it might be useful to all kinds of digital humanities researchers, and seek suggestions about tools you might like to use in the future Forensic Literary analysis? OCR on pictures of graffiti? Tell us!
See more, including video demos at hcsvlab.org.au/.
OR – we could link up with other NeCTAR tools/labs at THAT Camp and do a joint session comparing our approaches.
Peter Sefton, Dominique Estival and Denis Burnham – University of Western Sydney
Categories: General
Comments Off on Proposal: Talk about the Human Communications Science Virtual Lab
Data you can use, an evolutionary approach.
Data wranglers, back in the day, were spreadsheet wizards who could make any data sing to the tune of any report. Today we have data mashups magicians who can take data streamed from several places across the globe push them into Google gadgets displayed on any web page. They way we consume data today will undoubtedly change tomorrow. I have spent the last 5 years working with technology for a variety of humanities projects with a wide range of concepts, data modeling needs and data import requirements.
I would like to talk with researchers about their experience with data evolution throughout their research careers and the processes used to migrate data throughout the years. I hope that we get the opportunity to discuss approaches to evolving data across the decades, how to separate data models from work flows and why standards don’t last.
Categories: General
Comments Off on Data you can use, an evolutionary approach.
Down and dirty with mhealth tweets + SNA
 Mhealth policy conversations in social media are generating lots of data, but what can this tell us about the actors, their networked relationships or their investment in formal policy processes?
Mhealth policy conversations in social media are generating lots of data, but what can this tell us about the actors, their networked relationships or their investment in formal policy processes?
The Moving Media project has been exploring social network analysis of mhealth tagged tweets to better understand the informal policy networks that are developing on Twitter – but we’ve come up with some big questions about the analytical processes we’re using.
So we’d like to start a discussion about some of the challenges of doing SNA and network visualisations with this type of data, including things like:
- The types of tools that DH are using for SNA (Gephi vs Node XL)
- How to slice big data
- How to locate the data across maps
- How to automate the data scraping process
- How to share the data back with the users
We’d also like to know what you’re doing in this space and what discoveries you’ve made.
Categories: Coding, Data Mining, Linked Data, Mapping, Research Methods, Session Proposals, Session: Talk, Social Media, Text Mining, Visualization
Comments Off on Down and dirty with mhealth tweets + SNA
Make Session: Paperboy!
 Paperboy icon, with the permission of the Artist Bradley David Santos www.bradleydavidsantos.net/works%5B/caption%5D
Paperboy icon, with the permission of the Artist Bradley David Santos www.bradleydavidsantos.net/works%5B/caption%5D
The concept is to be able to search for articles by institutions and find collaborators who are publishing in your searched interests. Three different potential user groups have been considered:
– Prospective students who are searching for institutions to study at
– Academics who want to find collaborators at other institutions.
– Policy and institution-makers who want to look strategically at the published record to inform decisions.
This experimental project was initated at ‘healthhack’ in Melbourne over the weekend.
What was achieved during the weekend is described on the wiki.
github.com/healthhack-melb/wiki/wiki/Paperboy
(N.B, the live demo is being updated this evening. Look at it on Tuesday morning).
Coders, Designers, Analysts want to make stuff during the un-ference and teach some others a little?
Categories: Coding, Collaboration, Digital Literacy, Libraries, Mapping, Open Access, Session Proposals, Session: Make, Visualization
Comments Off on Make Session: Paperboy!
THATCamp Sydney 2013 – Less than 2 days to go!
Some excellent proposals – including this one and this one – have been posted so far. Why not add yours or pitch it live in
Categories: General
Comments Off on THATCamp Sydney 2013 – Less than 2 days to go!
Cleaning Data
Digital humanities data is generally messy. Sometimes it looks like the floor of a teenage bedroom. Before we can analyse the data we need to clean it up and organise it. There are many ways of doing this. One important tool to use is a spreadsheet.
In this session I will run through some basic techniques in Excel that are often used for cleaning up data. This session should be useful for those who are starting out in digital humanities.
It would be good if someone who is proficient with OpenRefine (formerly known as Google Refine) could share this session so participants can get a taste for that tool as well.
I”ve put some simple Excel tips in a document which you can access here.
Geospatial social media: human-powered sensing networks?
Geo-located social media provide a unique blend of information about society and place, extending volunteer geographic information models to form crowd-sourced people-centric data platforms. We propose a discussion around the use of geolocated social media in different disciplines.
The SMART Infrastructure Facility, University of Wollongong has developed a suite of tools, based on open software, for Twitter data analysis which we can present to kickstart conversations. It would be great to have some other presenters too.
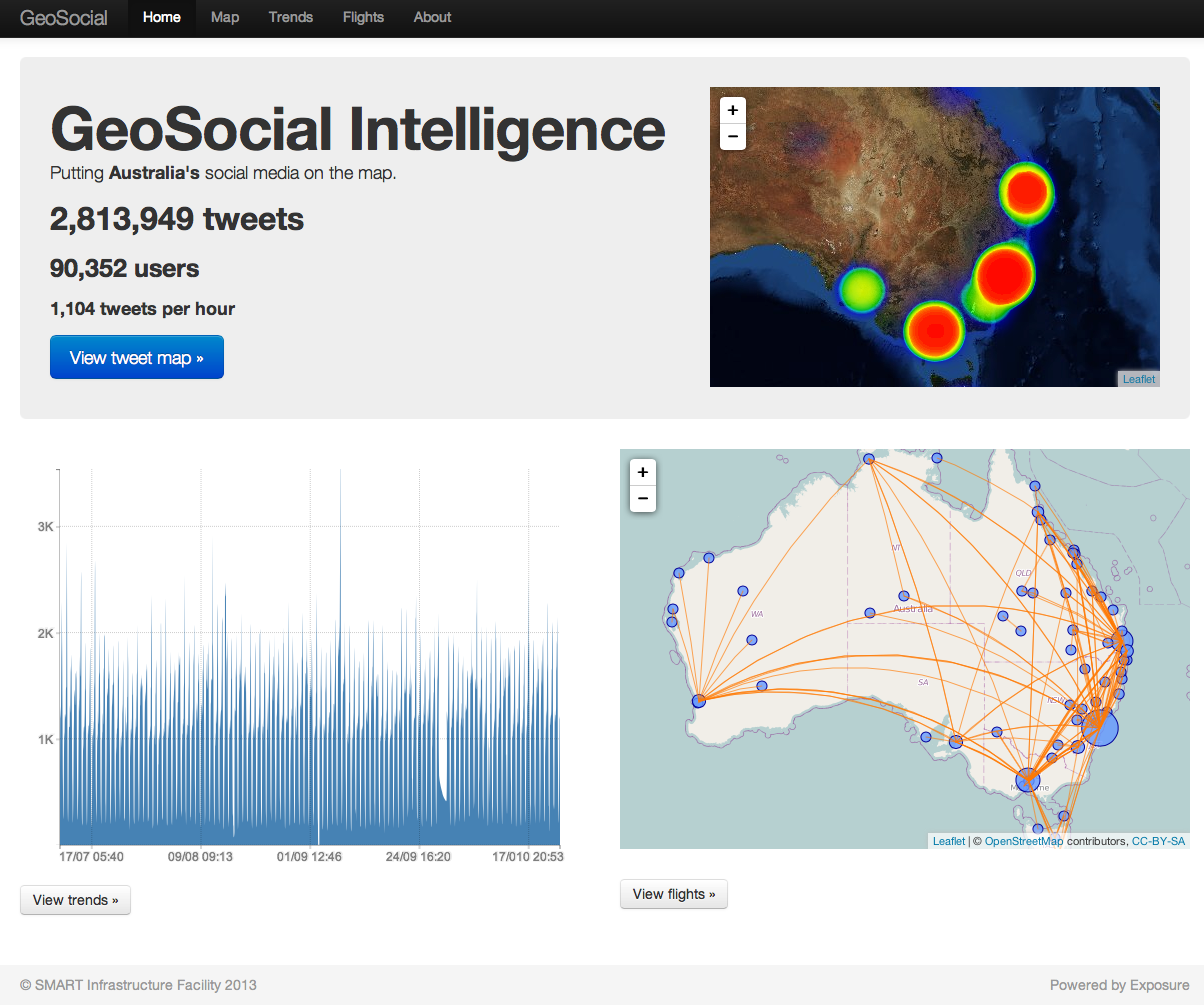
Geolocated tweets from around Australia
Interesting things we could discuss:
- How can we use geo-located social media to better understand the relationships between people and the urban environment?
- What is the role of social media during emergencies?
- Discussion on the technologies available to capture, analyse and visualise GeoSocial data.
Interested to hear your thoughts – all suggestions welcome!
Categories: Collaboration, Mapping, Session: Talk, Social Media, Visualization
Tags: Geography, Social Media
2 Comments
Less than 1 week to go – Post your session proposals!
Time to post your session proposals for THATCamp Sydney 2013 by logging in. Draw inspiration from reading the proposals already posted on the home page and reading the tips and suggestions.
Categories: General
Comments Off on Less than 1 week to go – Post your session proposals!
